Table of Contents
TL;DR: Why AI produces poor quality outputs
- Agents fail because they lack structured, task-relevant context, not because the model isn't good enough
- Adding more documents, longer prompts, and long lists of requirements often makes outputs worse, not better
- Traditional knowledge bases are built for humans to read, but are not optimized for agentic consumption
- Context engineering ensures the right information is delivered in the right format at the right time
- Reliable AI systems require structured knowledge, retrieval, and governance.
Introduction
AI agents produce incorrect or off-brand outputs primarily because they are given the wrong context, not because the models themselves are inadequate. Think: wrong tone, wrong messaging, inconsistent with your brand. So you fix it manually, one by one, every time.
Most teams respond the same way: they give the model more information... more documents, a larger knowledge base, longer prompts. It doesn’t work. Too little context produces bad outputs. Too much context produces the same problem: outputs that are still wrong, just longer and more confident.
The issue isn’t volume. It’s structure.
Your organizational knowledge (brand guidelines, tone rules, product positioning) exists in formats designed for humans to read, not for AI agents to apply. Until that changes, manual review remains part of the workflow.
Context engineering is what changes that.
What is context engineering and why does it matter for AI agents?
Context engineering is the process of structuring and delivering the right information to an AI agent so it can produce accurate, consistent outputs. It defines what AI sees before it generates an answer. This includes prompts, constraints, examples, guardrails, and relevant data. When done well, it reduces errors, improves output quality, and removes the need for manual correction.
Teams that invest in context engineering build systems where AI outputs are reliable by design. Teams that do not often rely on repeated human fixes to correct inconsistent results.
What is knowledge base software?
Knowledge base software are platforms for creating, organizing, and distributing information in a central, searchable location so teams and customers can find answers without manual intervention. Platforms like Notion, Confluence, Guru, Slab, Sharepoint, Glean, and Pinecone are all examples of knowledge bases (internal vs external). They are typically built for two audiences: employees (internal wikis, SOPs, onboarding guides) and customers (help centers, FAQs, product documentation).
In 2026, a third audience has emerged and it's the one most knowledge base platforms weren't designed for: AI agents. The result is a new category: the AI knowledge base, built not for humans to browse but for agents to query, retrieve from, and act on.
The difference matters. Humans browse, skim, and interpret. Agents query, retrieve, and apply, with no judgment about whether the context they received was the right context for the task. Feed them the wrong thing and they'll use it confidently.
Traditional knowledge base software vs. AI knowledge base software: what actually changed
Most teams assume the gap between traditional and AI knowledge base software is a feature gap. Better search. AI-generated summaries. Smarter recommendations. That's not the real difference.
The real difference is the consumer.
Traditional knowledge base software was designed with a human in the loop. The system surfaces documents. A person reads them, interprets them, and decides what applies to the situation. The human does the reasoning. The tool just retrieves. An AI knowledge base removes that human. The agent is both the retriever and the reasoner. It queries the knowledge base, pulls context, and immediately acts on it. There is no step where someone checks whether the retrieved context was actually the right context for this specific task.
Traditional knowledge base software optimizes for findability.
AI knowledge base software has to optimize for applicability. Not "can the system surface this document?" but "can the agent extract the specific rule it needs and apply it correctly to this task?"
Most platforms on the market have added AI features to traditional architectures. Semantic search, generative summaries, chatbot interfaces. These are retrieval improvements. They don't solve the applicability problem. An agent that retrieves your brand guide faster and summarizes it more fluently is still working from a document written for humans, not a structured rule set built for machines.
Why do AI agents fail without the right context?
The generative AI market spent the last three years racing to build faster, smarter models.
The assumption: better generation tools with more context produce better outputs. That assumption is wrong, and most marketing teams struggle with manual editing and intervention before content goes live.
The bottleneck was never generation. It's what you feed the model. Trash context in, trash content out, at every scale, with every tool. Claude, ChatGPT, Gemini, Jasper, and the rest are only as good as what you tell them. Right now, most teams are passing inconsistently formatted brand guidelines: guidelines buried in a Drive folder, tone rules in a doc nobody updates, product positioning that lives in someone's head.
Every team member rebuilds context from scratch for every tool. Every AI output requires manual review because the AI was never properly informed to begin with. File storage doesn't solve this. Enterprise search doesn't solve it. Prompt templates don't solve it. The context layer is completely unowned, and that's where quality breaks down.
There's a second failure that gets less attention: volume of context is not the same as quality of context. Teams that recognize the problem often overcorrect by feeding agents everything. Every brand document. Every guideline. Every past example. The agent receives a flood of context and produces outputs that are technically informed but practically unusable, averaging across too many inputs to produce anything precise.
Teams building AI content workflows see this pattern more than any other. Think: marketers, social media managers, communications professionals, PR agencies, you name it. The knowledge base gets bigger. The outputs don't get better. Sometimes they get worse: more confidently generic, more smoothly off-brand.
The model is doing exactly what you asked. You just asked it wrong.
The right context, at the right moment, in the right format is what produces reliable output. Volume is not the answer. Structure is.
Why do traditional knowledge bases fail AI agents?
If you're using Notion, Google Drive, or Confluence to store your brand guidelines, you have a knowledge base. What you don't have is context infrastructure.
Documents aren't queryable rules. Your brand guide is written for a human to read and interpret. An agent retrieving it gets a wall of prose with no way to extract which rule applies to this task, this audience, this format. The agent doesn't know that paragraph three of section two is the only part that matters for a LinkedIn post. It treats the whole document as equally relevant, which means you're leaving it up to the agent's discretion to successfully navigate the noise.
Nothing enforces compliance. The knowledge base holds the guidelines. But when the agent produces output that ignores them, nothing catches it. That's your job now. Every time. There is no feedback loop between output quality and the knowledge base. The system doesn't know it failed.
Retrieval isn't the same as relevance. Keyword search returns documents that contain the right words, not documents that contain the right context for what the agent is doing. An agent writing a LinkedIn post for a regulated industry needs different guardrails than one writing a product FAQ. Most systems treat them the same because they have no concept of what the agent is trying to accomplish.
Guidelines go stale without anyone noticing. Brand evolves. Messaging changes. Tone shifts after a rebrand. A knowledge base with no governance layer enforces last year's rules on today's content, and no one knows until a client complains or a piece goes live that shouldn't have.
As InfoWorld reported after speaking with engineers building agent systems at scale, "shared understanding" can become "shared misconception" fast when knowledge bases aren't actively maintained for agent consumption. The AI isn't confused, it's just using exactly what you gave it.
How does context engineering address poor quality outputs?
Where most teams try to fix AI quality with better prompts, context engineering treats it as an infrastructure problem. You shouldn't have to re-explain your brand to every tool, every workflow, every agent. That knowledge should be structured once and delivered intelligently everywhere.
Four operations make it work:
- Structuring: extracting brand rules, tone guidelines, compliance requirements, and messaging into formats agents can parse, not prose they have to interpret
- Retrieval: pulling context dynamically based on what the agent is doing, not what keywords matched
- Reduction: surfacing only what's relevant to the current task, not flooding the agent with everything it could know
- Governance: keeping the context layer current as your brand and guidelines evolve, so agents are always working from what's true now
The practical difference: an agent writing a client-facing email for a fintech brand gets your compliance language and formal tone. The same agent writing an Instagram caption gets your casual voice and visual copy rules. Automatically. Without a separate prompt for each. The knowledge base doesn't change. What changes is which part of it each agent sees.
Context engineering vs. RAG: what’s the difference?
RAG is a retrieval mechanism. Context engineering is the full system: how knowledge is structured before retrieval, what gets retrieved for which task, how output is evaluated against what was retrieved, and how the knowledge layer is kept accurate over time.
How do you build a knowledge base that works for AI agents?
Most guides on building an AI knowledge base focus on content organization: folder structure, tagging systems, metadata schemas. These matter, but they're downstream of a more fundamental question: what format does your knowledge need to be in for an agent to act on it correctly?
The answer is not a document. It's a rule set.
1. Start with extraction, not creation. Most organizations already have the knowledge they need. Brand guidelines exist. Tone-of-voice documents exist. Compliance rules exist. The problem is they're written for humans. The first step is extracting the operative rules from those documents and restructuring them as discrete, labeled statements scoped to specific contexts. Not "our brand voice is warm and direct" but "when writing for [audience], use [specific tone], avoid [specific patterns], lead with [specific structure]."
2. Scope rules to tasks, not topics. A rule that applies to all content is less useful than a rule that applies to email subject lines, or regulated product claims, or agency client deliverables. The more precisely a rule is scoped, the more precisely an agent can apply it. Generic guidelines produce generic outputs.
3. Assign ownership to every rule. Every entry in the knowledge base should have a named owner and a review date. Without this, the knowledge base drifts. Guidelines updated in a rebrand six months ago don't make it in. Compliance language updated after a legal review stays in the old version. Ownership and cadence are not administrative overhead — they're what keeps the system producing accurate outputs six months from now.
4. Evaluate outputs against the knowledge base, not against human intuition alone. If the only quality check is a person deciding whether something feels right, the knowledge base is decorative. The check needs to be systematic: outputs scored against the rules they were generated from, flagged when they miss, rewritten before they ship.
One thing a team can do today, without any new tooling: take one document from your knowledge base — your brand guidelines, your tone guide, whatever is most frequently used to brief AI — and extract twenty discrete rules from it. Numbered, scoped to specific task types, written as instructions rather than descriptions. Run your next AI output against that list manually. The gap between what the rules say and what the output does is the size of your context problem.
The context infrastructure framework for AI agents
Fixing the knowledge base problem for AI requires rethinking the architecture entirely. Not storage. Infrastructure.
┌──────────────────────────────────────────┐
│ AI Agent / Workflow │
├──────────────────────────────────────────┤
│ Task-Aware Context Delivery │
│ Right context, right moment, │
│ right format │
├──────────────────────────────────────────┤
│ Governance and Brand Scoring │
│ Flags drift, enforces rules, │
│ auto-rewrites off-brand outputs │
├──────────────────────────────────────────┤
│ Structured Knowledge Base │
│ Extracted, tagged, agent-ready │
└──────────────────────────────────────────┘
Structured Knowledge Base: Brand guidelines, tone rules, compliance requirements, and product positioning are extracted from source documents and stored in a format agents can query, not browse. The distinction is critical: a browsable document is organized for a human navigating it. A queryable knowledge base is organized around the rules themselves, tagged by context, audience, format, and task type so an agent can retrieve exactly what it needs without interpreting surrounding prose.
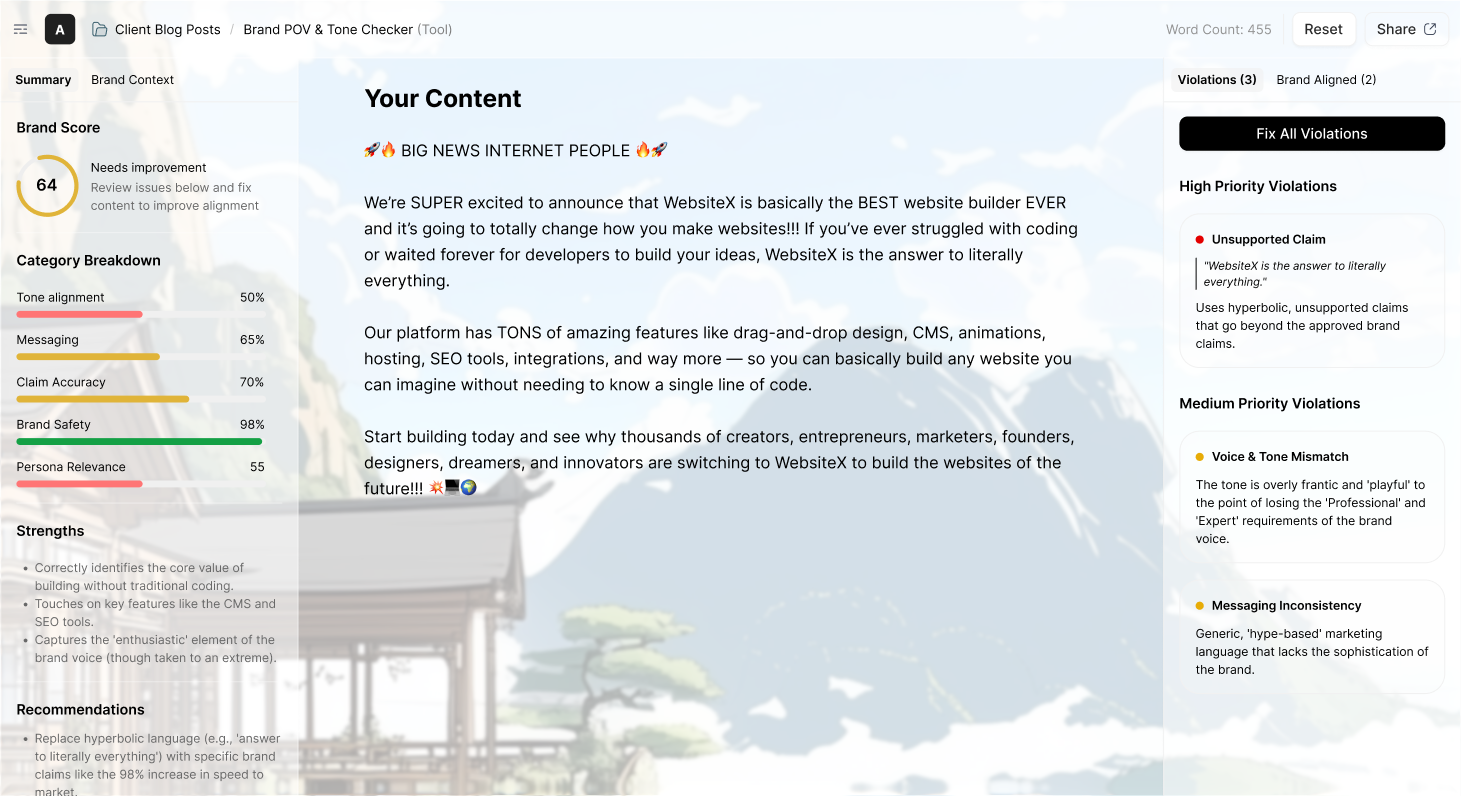
Governance and Brand Scoring: Every AI output is evaluated against the knowledge base automatically. Off-brand content is flagged before it reaches a human reviewer. A brand score quantifies how well the output adheres to your standards across tone, messaging, claims, and format. Outputs that miss are rewritten, not just flagged, so the feedback is immediate and the fix is done. This is the layer most knowledge base platforms skip entirely. They surface knowledge. They don't enforce it.
Task-Aware Context Delivery: When an agent begins a task, it receives the specific context relevant to that task, not a dump of everything it could know. The system understands what the agent is doing and surfaces the rules that apply to it. A social post gets social voice rules. A regulated claim gets compliance language. A client-facing proposal gets the tone profile for that client's industry. This goes beyond keyword retrieval. It requires the knowledge base to be structured around tasks, not topics.
The Agent: With the right context delivered correctly, agents produce accurate, on-brand outputs without a manual review cycle sitting behind every one. The improvement is not in the model. It's in what the model was given to work with.
The three most common knowledge base mistakes that break AI outputs
These patterns appear consistently across teams deploying AI at scale. Each one is fixable. None of them require switching models.
Mistake 1: Treating RAG as a complete solution.
RAG retrieves documents. It doesn't structure them, scope them to tasks, or enforce output quality against them. Teams that implement RAG and consider the context problem solved find that outputs improve marginally, then plateau. The knowledge base still contains documents written for humans. The retrieval is faster and more semantic. The applicability problem is unchanged. RAG is a better library catalog. It's not a context layer.
Mistake 2: Confusing more context with better context.
The instinctive response to inconsistent AI outputs is to add more to the knowledge base. More examples. More guidelines. More documents. This increases noise more than precision. Agents averaging across a large, unstructured context pool produce outputs that are diluted, not improved — smoothly written, technically compliant with something in the knowledge base, but not actually right for this task. The goal is not a comprehensive knowledge base. It's a precise one. Every rule that doesn't apply to the current task is context that works against you.
Mistake 3: Building the knowledge base once and never governing it.
Brand guidelines written eighteen months ago are not the same as brand guidelines today. Messaging evolves. Positioning shifts. Compliance requirements change. A knowledge base with no governance layer becomes a source of confident, systematically wrong outputs. And because the errors are consistent — everything sounds like the same brand, just the old one — they're harder to detect. The most dangerous knowledge base is one that feels like it's working.
What this means for marketing teams using AI at scale
If you're a marketing manager using AI to produce content at volume, the current workflow probably looks like this:
- Brief the AI or use a template
- Review the output
- Rewrite the parts that are off-tone, wrong on messaging, or inconsistent with how your brand actually speaks
- Repeat for the next asset
Steps 2 through 4 become a tax on productivity incurred by team members who are using AI the most. Context engineering eliminates them. Not by making the model smarter, but by making it better-informed. The guidelines it needed were always there. They just weren't in a format it could actually use.
After implementing an agentic knowledge base, LinkedIn saw issue triage time drop by approximately 70% across many areas. Not because their models improved. Because their agents finally had the organizational context they needed to work correctly.
That's the compounding effect. The ideal state. The holy grail. Every agent connected to a governed, structured context layer gets more reliable over time as guidelines are updated and enforced automatically. Teams still copy-pasting guidelines into prompts don't get that... and their AI quality is only as good as whoever wrote the prompt that day.
How Source approaches context infrastructure
Source is built as context infrastructure for AI agents. It centralizes brand guidelines, tone rules, and organizational knowledge into a single structured layer, then delivers that context to any agent or workflow via MCP, API, SDK, or Chrome extension.
What we see in practice: teams that connect Source to their existing AI workflows stop treating brand review as a step in the process. The knowledge base built into the product understands your brand, while a separate agent optimized for scoring does the enforcement. Outputs arrive scored, flagged, and fixed where they missed. The manual review cycle shrinks to edge cases rather than standard practice.
With Source, the context layer stays current as your brand evolves. Source doesn't replace your AI tools. It makes them work for your company, consistently, across every tool and workflow, without the overhead sitting behind every output right now.
Interested in Source's brand checker?
Frequently Asked Questions
What is a knowledge base used for?
A knowledge base stores and organizes information so people or systems can retrieve answers without asking a human. In customer support, it deflects tickets. In internal operations, it preserves institutional knowledge. For AI agents, it serves as the source of structured context they need to produce accurate, consistent outputs. The use case has expanded significantly as organizations deploy agents at scale.
What is the difference between a knowledge base and a database?
A database stores raw, structured data (records, transactions, logs) optimized for querying and processing. A knowledge base stores curated, meaningful content (guidelines, procedures, rules) optimized for retrieval and reasoning. AI agents need both, but they depend on knowledge bases to understand how to behave, not just what data exists.
What is the difference between a traditional knowledge base and an AI knowledge base?
A traditional knowledge base is organized for humans to browse and interpret. An AI knowledge base is organized for agents to query and act on. The structural difference is fundamental: traditional systems surface documents, while AI knowledge bases surface rules, scoped to tasks, in formats agents can apply without human interpretation in between.
What is the difference between a knowledge base and context engineering?
A knowledge base is the repository where organizational knowledge is stored. Context engineering is the discipline of structuring, governing, and delivering that knowledge so AI agents can apply it correctly. You can have a knowledge base without context engineering. What you get is a folder of documents that agents access inconsistently. Context engineering turns that folder into infrastructure.
How does RAG relate to knowledge base software?
RAG (retrieval-augmented generation) pulls documents from a knowledge base into an agent's context window at generation time. Context engineering goes further: it structures the knowledge in agent-ready formats before retrieval, governs what gets surfaced for each task type, and enforces output quality against the retrieved rules. RAG is a retrieval mechanism. Context engineering is the full system it operates inside.
Why do AI agents produce off-brand content?
Because they were never properly informed to begin with. Brand guidelines stored in PDFs or Notion docs are accessible, not consumable. Agents receive too much irrelevant context, too little specific guidance, and no enforcement layer to catch drift after generation. Adding more documents makes this worse. The fix is structured, governed, task-aware context delivery.
What features should knowledge base software have for AI agents?
For agent-native workflows, the critical features are structured knowledge extraction (not just document storage), task-aware retrieval (not keyword search), automated output scoring against brand standards, governance to keep the context layer current, and integrations that connect to your existing AI stack via MCP, API, or SDK. Most knowledge base platforms on the market today were built for human consumers and offer none of these.